BAZY DANYCH

BAZY DANYCH
Podstawowe pojęcia
Relacyjna baza danych
Baza danych pozwalająca na sprawne przechowywanie, zarządzanie oraz operowanie danymi zorganizowanym w struktury zwane relacjami.
Relacja
Podstawowym i jedynym sposobem reprezentowania danych w modelu relacyjnym jest relacja, będąca dwuwymiarową tablicą. Relacja jest zbiorem krotek posiadających taką samą strukturę, lecz różne wartości. Zdefiniowana relacja zawiera określony zbiór atrybutów (kolumn) i dowolną ilość niepowtarzalnych krotek (wierszy).
Atrybut
W nagłówku relacji podane są atrybuty. Służą one do nazywania kolumn relacji. Na ogół oddają znaczenie danych umieszczanych w kolumnach pod nimi. Z każdym atrybutem powiązana jest dziedzina (typ danych) przy pomocy której reprezentowane są jego wartości.
Krotka
Wiersze relacji, poza wierszem nagłówka (zawierającym atrybuty relacji), nazywane są krotkami. W krotce każdy atrybut posiada swój odpowiednik w postaci składowej krotki. Każda krotka reprezentuje pojedynczy i niepowtarzalny wpis do tabeli relacji. Inne nazwy krotki to rekord lub encja.
Dziedzina
W modelu relacyjnym każdy atrybut relacji musi mieć określony atomowy typ danych, tzn. jego typ musi należeć do typów elementarnych, np. musi być to typ liczbowy lub znakowy. Wartość atrybut nie może być ani rekordem (krotką), ani listą, ani tablicą, ani zbiorem, ani jakąkolwiek inną strukturą, którą można podzielić na mniejsze części.
Schemat relacji
Nazwa relacji oraz zbiór jej atrybutów nazywają się schematem relacji. W modelu relacyjnym projekt składa się z jednego lub wielu schematów relacji. Zbiór schematów relacji projektu jest określany schematem relacyjnej bazy danych.
Przykład relacji
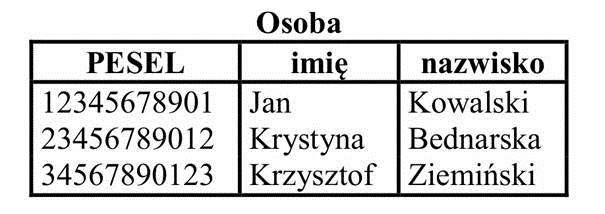
Legenda:
· „Osoba” to nazwa relacji (tabeli)
· Wiersz nagłówka zawiera nazwy atrybutów: PESEL, imię, nazwisko
· Nazwa relacji wraz z nazwami atrybutów stanowią schemat relacji:
· Osoba (PESEL, imię, nazwisko)
· Każdy z wierszy poza wierszem nagłówka stanowi krotkę (rekord, wiersz) relacji
· Kolejne pozycje każdej krotki stanowią wartości z dziedzin odpowiadających atrybutów
PODSTAWOWE DEFINICJE
Baza danych (database) – uporządkowany magazyn danych – informacji powiązanych tematycznie, umożliwiający ich wyszukiwanie według zadanych kryteriów
Baza danych składa się z jednej lub wielu tabel.
Tabela (table) – dwuwymiarowa struktura przechowująca dane dotyczące określonego tematu
- kolumny – pola (atrybuty), część tabeli przechowująca jednostkowe typy danych np. nazwisko konkretnej osoby.
- wiersze – rekordy (krotki), to pojedynczy wiersz w tabeli, czyli zestaw pól w niej występujących. Np. może to być zestaw cech danego człowieka: pesel, imię, nazwisko, data urodzenia, adres.
Kwerenda - (z ang. query) - inaczej zapytanie do bazy danych. Istnieje wiele rodzajów zapytań, m.in: kwerendy wybierające, aktualizujące, usuwające, dołączające, krzyżowe, tworzące tabele etc. Np. kwerenda wybierająca może dla nas znaleźć w bazie wszystkich ludzi o danym nazwisku.
Formularz - służy do wygodnego wprowadzania, edytowania i usuwania danych w tabeli. Wymienione operacje wykonuje się za pomocą okna w którym użytkownik obsługuje pola. Znaczenie pól opisane jest za pomocą etykiet, można też wprowadzić mechanizmy wykrywania poprawności wypełnienia formularza (tzw. walidacja poprawności danych)
Raport - to informacje wyjęte z bazy danych, sformatowane i poukładane w czytelny dla odbiorcy sposób, tak aby można było je przedstawić np. na wydruku
Procedura - Procedurą nazywamy serię poleceń zapisaną w języku programowania baz danych, służącą do wykonywania obsługi na elementach bazy: tabelach, formularzach, raportach, kwerendach.
Sortowanie - Sortowaniem rekordów nazywamy ich porządkowanie według jakiegoś kryterium. Kryterium to nazwa lub nazwy pól według których odbywa się sortowanie.
Przykładowo może być to sortowanie rosnące (sortuje wartości w porządku rosnącym (od A do Z, albo od 0 do 9) lub sortowanie malejące (sortuje wartości w porządku malejącym od Z do A, od 9 do 0)
TYPY DANYCH - W każdej kolumnie tabeli w bazie przechowane są dane jednakowego typu. Systemy zarządzania bazami danych oferują wiele typów danych, m.in.:
|
Typ |
Rozmiar |
Opis |
|
CHAR[x] |
x bajtów |
Pole przechowujące od 0 do max. 255 znaków |
|
VARCHAR[x] |
Długość łańcucha x + 1 bajt |
Pole tekstowe o zmiennej długości |
|
TEXT |
Długość łańcucha + 2 bajty |
Łańcuch o maksymalnej długości 65535 znaków |
|
LONGTEXT |
Długość łańcucha + 4 bajty |
Łańcuch o maksymalnej długości 4294967295 znaków |
|
INT |
4 bajty |
Liczby z zakresu od -2147483648 do 2147483647 |
|
FLOAT |
4 bajty |
Liczba rzeczywista, zmiennoprzecinkowa |
|
DATE |
3 bajty |
Data w formacie YYYY-MM-DD |
|
TIME |
3 bajty |
Data w formacie HH:MM:SS |
NULL - jeśli dana wartość nie jest znana lub nie ma jej w ogóle, to mówimy, że jest to wartość NULL (to nie to samo co 0 lub znak spacji).
SQL - jest akronimem pochodzącym od Structured Query Language (strukturalny język zapytań kierowanych do bazy danych). Jest to język opracowany przez firmę IBM w celu współpracy z relacyjnymi bazami danych. SQL stał się standardem w komunikacji z relacyjnymi bazami danych. Dziś SQL-a spotkamy najczęściej w trzech systemach zarządzania bazami: MySQL firmy Oracle, PostgreSQL opracowany na uniwersytecie w Berkeley oraz FireBird korporacji Borland.
Funkcje bazy danych
Funkcje zależne od użytkownika:
- tworzenie baz danych i tabel
- wyszukiwanie danych
- dodawanie i usuwanie danych
- czynności administracyjne
Funkcje zależne od oprogramowania:
- zarządzanie fizycznymi zbiorami danych
- wykonywanie poleceń użytkownika
- prezentacja wyników operacji
Typy baz danych
Najczęściej spotykane typy baz danych
- Proste bazy danych o pojedynczej tabeli (np. Excel)
- Jednostanowiskowa baza biurowa (np. MS Access)
- Baza typu „klient-serwer” – dostęp z wielu stanowisk (np. Oracle)
- Internetowa baza danych – dostęp z dowolnego komputera podłączonego do Internetu (z zastosowaniem języka SQL)
- Bazy rozproszone
Relacyjne bazy danych
Relacyjna baza danych to zbiór danych zawartych w wielu tabelach połączonych ze sobą relacjami (związkami) –jedna tabela dla każdego typu informacji
· optymalizacja dla dużej ilości danych
· zalety: szybsze wyszukiwanie
· Zaleta systemu obsługi relacyjnych baz danych polega na zdolności do szybkiego wyszukiwania i kojarzenia informacji przechowywanych w odrębnych tabelach.
· Realizacja tego celu wymaga obecności w tabeli pola lub ich zestawu jednoznacznie identyfikującego każdy rekord zapisany w tabeli.
· Pole to lub ich zestaw nosi nazwę klucza podstawowego tabeli (primarykey).
· Po zdefiniowaniu w tabeli klucza podstawowego, nie będzie można w jego pole wprowadzić wartości już istniejącej w tabeli ani wartości Null (pustej).
Klucze tabeli
Klucz podstawowy (ang. primary key) zwany też kluczem głównym to jedno lub więcej pól, których wartość jednoznacznie identyfikuje każdy rekord w tabeli. Taka cecha klucza nazywana jest unikatowością.
Najważniejsze typy klucza podstawowego:
•klucze podstawowe jednopolowe
•klucze podstawowe wielopolowe – gdy żadne z pól nie gwarantuje, że wartości w nim zawartych będą unikatowe
•klucze typu „autonumeracja” (auto increment) – licznik zwiększany automatycznie przy dodawaniu nowego rekordu
Indeksowanie tabeli
Pole indeksowane –przyspiesza wyszukiwanie i sortowanie tabeli wg. indeksowanego pola
•klucz podstawowy jest zawsze indeksowany
•niektóre pola nie mogą być indeksowane z uwagi na typ pola
•indeksy przyspieszają wyszukiwanie, ale mogą też powodować spowolnienie aktualizacji dużych rekordów
•nie należy stosować indeksu, jeśli indeksowane pola nie są używane do wyszukiwania, sortowania lub sprzężenia
•usunięcie indeksu nie powoduje usunięcia pola ani danych wprowadzonych w polu
Pola unikalne i niepuste
Pola unikatowe (unique):
- system bazy danych sprawdza, czy zawartość pola nie pokrywa się z już istniejącymi rekordami
- niemożliwe jest wprowadzenie dwóch rekordów o identycznej zawartości pola unikatowego
- klucz podstawowy jest z definicji polem unikatowym
Pola niepuste (not null)
- system bazy danych sprawdza, czy pole posiada zawartość, zapobiega wprowadzeniu rekordu z polem pustym, jeżeli pole to ma atrybut not null
- klucz podstawowy jest z definicji polem niepustym
Relacje opisują sposób powiązania informacji zawartych w wielu tabelach.
Relacja –związek ustanowiony pomiędzy wspólnymi polami (kolumnami) w dwóch tabelach.
Relacja działa poprzez dopasowanie danych w polach kluczowych —zwykle są to pola o tej samej nazwie w obu tabelach. W większości przypadków dopasowywane pola to klucz podstawowy z jednej tabeli, który dostarcza unikatowego identyfikatora dla każdego rekordu, oraz klucz obcy w drugiej tabeli.
Klucz obcy
Klucz obcy (foreign key) –jedno lub kilka pól (kolumn) tabeli, które odwołują się do pola lub pól klucza podstawowego w innej tabeli.
Klucz obcy wskazuje sposób powiązania tabel relacjami
- typy danych w polach klucza podstawowego i obcego muszą być zgodne
- nazwy pól klucza podstawowego i obcego nie muszą być identyczne
Relacja „jeden do wielu”
Relacja pomiędzy tabelami „jeden do wielu” (one-to-many) oznaczenie 1 - N:
- rekord w tabeli A może mieć wiele dopasowanych do niego rekordów z tabeli B, ale rekord w tabeli B ma tylko jeden dopasowany rekord w tabeli A
- najczęściej występujący typ relacji
Przykład:
•do jednego wykonawcy przypisanych jest wiele płyt CD
•każda płyta CD ma tylko jednego autora
Relacja „wiele do wielu”
Relacja pomiędzy tabelami „wiele do wielu” (many-to-many) oznaczenie N - N
•Rekord w tabeli A może mieć wiele dopasowanych do niego rekordów z tabeli B i tak samo rekord w tabeli B może mieć wiele dopasowanych do niego rekordów z tabeli A.
•Jest to możliwe tylko przez zdefiniowanie trzeciej tabeli (nazywanej tabelą łącza), której klucz podstawowy składa się z dwóch pól —kluczy obcych z tabel A i B.
•Relacja wiele-do-wielu jest w istocie dwiema relacjami jeden-do-wielu z trzecią tabelą.
Relacja „jeden do jednego”
Relacja pomiędzy tabelami „jeden do jednego” (one-to-one) oznaczenie 1 - 1
•W relacji jeden-do-jednego każdy rekord w tabeli A może mieć tylko jeden dopasowany rekord z tabeli B, i tak samo każdy rekord w tabeli B może mieć tylko jeden dopasowany rekord z tabeli A.
•Ten typ relacji spotyka się rzadko, ponieważ większość informacji powiązanych w ten sposób byłoby zawartych w jednej tabeli. Relacji jeden-do-jednego można używać do podziału tabeli z wieloma polami, do odizolowania długiej tabeli ze względów bezpieczeństwa, albo do przechowania informacji odnoszącej się tylko do podzbioru tabeli głównej.
RODZAJE KWEREND
1. KWERENDA WYBIERAJĄCA
Kwerenda wybierająca jest najczęściej używanym rodzajem kwerendy, służy do wybierania danych z jednej tabeli lub kilku tabel bazy danych i wyświetlania wyników w postaci arkusza danych.
2. KWERENDA MODYFIKUJĄCA
Pozwala na wprowadzenie zmian w wielu rekordach. Istnieją cztery rodzaje kwerend modyfikujących: usuwająca, aktualizująca, dołączająca i tworząca tabele.
- KWERENDA USUWAJĄCA
Usuwa grupę rekordów z jednej lub kilku tabel. Użycie kwerendy usuwającej powoduje usunięcie całych rekordów, nie zaś wybranych pól w rekordach.
- KWERENDA AKTUALIZUJĄCA
Dokonuje globalnych zmian w grupie rekordów w tabeli lub kilku tabelach. Za pomocą kwerend aktualizujących można zmienić dane w istniejących tabelach.
- KWERENDA DOŁĄCZAJĄCA
Dodaje grupę rekordów z tabeli lub tabel na końcu innej tabeli lub tabel. Kwerendy dołączające są również przydatne w następujących sytuacjach:
- dołączanie pól wybranych na podstawie kryteriów;
- dołączanie rekordów w sytuacjach, gdy część pól jednej tabeli nie ma swoich odpowiedników w drugiej tabeli.
- KWERENDA TWORZĄCA TABELĘ
Tworzy nową tabelę z wszystkich lub części danych znajdujących się w jednej lub kilku tabelach. Kwerendy tworzące tabelę są przydatne w następujących sytuacjach:
- tworzenie tabel, które mają być eksportowane do innych baz danych programu Microsoft Access;
- tworzenie raportów zawierających dane od określonego momentu;
- tworzenie kopii zapasowej tabeli;
- tworzenie tabeli archiwalnej, zawierającej nieaktualne rekordy;
- poprawianie sprawności działania formularzy i raportów utworzonych na podstawie kwerend korzystających z danych z wielu tabel lub instrukcji SQL
3. KWERENDA KRZYŻOWA
Wyświetla zliczone wartości z pola i porządkuje wartości w wiersze i kolumny. Łączy analizy zliczania oraz sumowania. Ma budowę zbliżoną do tabeli, gdyż składa się z wierszy i kolumn.
Każdy wiersz to oddzielny rekord, a kolumna to pole w danym rekordzie. Niekiedy kwerenda powinna zawierać jedynie ograniczony zakres danych.
Etapy projektowania relacyjnej bazy danych
Etap 1 –Określenie celu, jakiemu ma służyć baza danych:
•jakich informacji ma dostarczyć baza danych
•jakie zagadnienia będą analizowane w bazie (tabele)
•jakie informacje mają określać każde zagadnienie (pola w tabelach)
•konsultacja z przyszłymi użytkownikami bazy danych
•naszkicować wzory raportów, które powinna wytwarzać
•zgromadzić formularze do wpisywania danych, które są używane obecnie
•zapoznać się z działaniem dobrze zaprojektowanych baz danych, podobnych do tej, która ma być utworzona
Etap 2 –Określenie tabel, które są potrzebne w bazie danych:
•tabela nie powinna zawierać powtarzających się informacji, a informacje nie powinny powtarzać się w różnych tabelach –dane wystarczy aktualizować w jednym miejscu
•każda tabela powinna zawierać informacje tylko na jeden temat –dane na temat jednego zagadnienia można przetwarzać niezależnie od danych dotyczących innych zagadnień
Etap 3 –Określenie pól, które są potrzebne w tabelach:
•należy powiązać każde pole bezpośrednio z zagadnieniem, którego dotyczy tabela
•nie należy wprowadzać danych pośrednich lub obliczonych (danych, które są wynikiem wyrażenia)
•należy uwzględnić wszystkie potrzebne informacje
•informacje należy przechowywać w możliwie najmniejszych jednostkach logicznych (na przykład Imię oraz Nazwisko, a nie Dane personalne)
Etap 4 –Przypisanie polom jednoznacznych wartości w każdym rekordzie
•Aby program bazy danych mógł powiązać informacje przechowywane w różnych tabelach, każda tabela w bazie danych musi zawierać pole lub zbiór pól, które jednoznacznie określają każdy rekord. Takie pole lub zbiór pól nazywany jest kluczem podstawowym.
•Klucz podstawowy (primarykey) –jedno lub więcej pól, których wartości w sposób jednoznaczny identyfikują dany rekord w tabeli. Klucz podstawowy nie może być pusty (NULL) i zawsze musi mieć indeks unikatowy
Etap 5 –Określenie relacji między tabelami
•Po podzieleniu danych na tabele i zdefiniowaniu pól kluczy podstawowych trzeba określić sposób poprawnego łączenia powiązanych danych w logiczną całość.
•W tym celu definiuje się relacje między tabelami w bazie danych.
Etap 6 –Wprowadzenie danych i utworzenie innych obiektów bazy danych
Zakończenie etapu projektowego:
- sprawdzenie projektu i wykrycie ewentualnych usterek
Po zakończeniu etapu projektowego należy:
- utworzyć bazę danych i tabele
- wprowadzić dane do bazy
- utworzyć potrzebne formularze, strony dostępu do danych, skrypty i moduły
Etap 7 –Testowanie i udoskonalanie bazy danych
•praktyczna weryfikacja projektu
•sprawdzenie poprawności wyników zapytań
•testowanie szybkości działania bazy
•optymalizacja i reorganizacja bazy, ew. poprawa projektu i utworzenie bazy od nowa
•testowanie z udziałem użytkowników bazy –serwis
Optymalne projektowanie tabel
Optymalizacja tabel pod kątem ich wydajności
•Należy projektować tabele bez danych nadmiarowych
•Należy wybierać odpowiednie typy danych dla każdego z pól. Podczas definiowania danego pola, należy wybrać typ danych wymagający możliwie najmniej pamięci i odpowiedni dla danych przechowywanych w polu
•Należy tworzyć indeksy dla pól, które są sortowane, sprzęgane lub dla których ustawiane są kryteria
•Zbyt duża liczba indeksów spowalnia działanie bazy
Wybór typu pola
Przy podejmowaniu decyzji, jakiego typu danych użyć w polu tabeli, należy uwzględnić następujące czynniki:
•Jakie wartości będą dozwolone dla pola?
•Ile miejsca będą mogły zajmować dane przechowywane w polu?
•Jakie operacje będą wykonywane na wartościach w polu?
•Czy wartości w polu będą sortowane lub indeksowane?
•Czy pole będzie używane do grupowania rekordów w kwerendach lub raportach?
•W jaki sposób wartości pola będą sortowane?
System zarządzania bazą danych SZBD
System Zarządzania Bazą Danych (SZBD, ang. DBMS) – uniwersalny system programowy, umożliwiający tworzenie, obsługę i ochronę baz danych w różnych zastosowaniach, inaczej mówiąc to zbiór komponentów służących do definiowania, konstruowania i modyfikowania bazy danych.
SZRBD – system zarządzania relacyjną bazą danych, przechowuje również związki między danymi
Budowa SZRDB:
•interfejs aplikacji –komunikacja użytkownika z bazą
•interpreter SQL –tłumaczenie języka SQL na kod wewnętrzny
•moduł dostępu do danych
•baza danych –fizyczne pliki z danymi
Zadania SZBD
•Realizuje procedury niskiego poziomu, które pozwalają utrzymać dane w określonej postaci
•Przeprowadza wszelkie operacje odczytu i zapisu z/do plików lub urządzeń o bezpośrednim dostępie na serwerze bazy danych
•Zapewnia mechanizmy szybkiego dostępu do danych
•Zmniejsza lub wyklucza konieczność przechowywania nadmiarowych danych
•Optymalizuje sposób przechowywania danych
•Zapewnia integralność i spójność danych
Zalety SZBD
•optymalne zarządzanie złożonymi, relacyjnymi danymi
•dostęp do danych niezależny od oprogramowania i sprzętu
•pozwala na wykonywanie wielu jednoczesnych operacji na danych przez wielu użytkowników
•szybsze wyszukiwanie danych
•bezpieczeństwo danych (autoryzacja dostępu)
•usługi zarządzania bazą
•korzystanie z gotowego oprogramowania
Kiedy warto stosować SZBD?
•duża ilość danych
•jednoczesny dostęp wielu użytkowników
•istnieją powiązania pomiędzy danymi
•więcej niż jeden rodzaj rekordu
•ograniczenia danych (np. długość pola)
•potrzeba uzyskiwania raportów z danych
•potrzeba szybkiego wyszukiwania danych wg złożonych kryteriów
•potrzeba łatwego dodawania, usuwania i modyfikowania danych
Ogólna struktura zabezpieczeń systemów informatycznych:
- fizyczne zabezpieczenie dostępu do systemu,
- personalna odpowiedzialność za dostęp do systemu,
- mechanizmy zabezpieczeń systemu operacyjnego i sieci komputerowej,
- mechanizmy zabezpieczeń baz danych
I. Zagrożenia dla baz danych:
1) Zagrożenia wynikające z umyślnego działania nieuprawnionych użytkowników.
a) nieuprawniony odczyt,
b) nieuprawniony i niepoprawny zapis / modyfikacja,
2) Zagrożenia wynikające z błędów (użytkowników, oprogramowania i sprzętu) i zdarzeń losowych:
a) pomyłki użytkowników przy wprowadzaniu i aktualizacji danych,
b) niepoprawna modyfikacja wynikająca z niekontrolowanego współbieżnego dostępu do danych,
c) niepoprawna modyfikacja wynikająca z błędów programów i awarii systemu,
d) zniszczenie danych przy poważnych awariach sprzętu,
II. Kierunki przeciwdziałania zagrożeniom:
1) Polityka bezpieczeństwa w systemach baz danych:
a) kontrola dostępu,
b) monitorowanie b.d.,
c) szyfrowanie w b.d.,
2) Ochrona integralności baz danych:
a) Integralność semantyczna: - ograniczenia dziedzin atrybutów, - więzy referencyjne,
b) Integralność transakcyjna: - mechanizmy blokad, - prowadzenie dziennika transakcji.
Kontrola dostępu do baz danych:
- identyfikacja użytkowników,
- autentyfikacja (uwierzytelnianie) użytkowników,
- autoryzacja użytkowników – przydzielanie uprawnień użytkownikom a następnie egzekwowanie ograniczeń, które wynikają z tych uprawnień.
Kontrola dostępu w języku SQL (DCL - Data Control Language)
- Tworzenie użytkowników,
- Nadawanie uprawnień ogólnych (systemowych),
- Nadawanie uprawnień szczegółowych (obiektowych)
Monitorowanie baz danych – instrukcja AUDIT:
- monitorowanie operacji (poleceń),
- monitorowanie obiektów,
- monitorowanie uprawnień.
Szyfrowanie w bazach danych:
- szyfrowanie haseł,
- szyfrowanie procedur,
- szyfrowanie danych.


Komentarze